🚨 LLM Deep Dive Series (2 of 7): The Architecture of LLMs: From Transformers to Massive Parameters 🧠🤖
In this second post of the LLM Deep Dive Series, we focus on the architecture that powers modern Large Language Models (LLMs)—Transformers. The Transformer architecture has revolutionized natural language processing (NLP) and lies at the heart of powerful models like GPT-4. In this post, we’ll explore how Transformers work, the role of self-attention, and why scaling up these models with massive parameters leads to more sophisticated, albeit complex, AI.
What Is a Transformer?
The Transformer model, introduced in the groundbreaking 2017 paper “Attention Is All You Need” by Vaswani et al., was a pivotal moment in the development of AI models. Before Transformers, models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks were widely used for sequence data like text. These earlier models processed input sequentially, meaning each word or token was passed through the network one after the other. This sequential processing was slow, and it made it harder for models to understand long-range dependencies between words or phrases in a sentence.
The Transformer changed all of this. It introduced a new mechanism—self-attention—which allowed the model to process input in parallel and directly compute relationships between tokens (words or phrases), regardless of their position in a sequence. This not only improved efficiency but also vastly improved performance on NLP tasks.
Inner Workings of the Transformer: Layers and Mechanisms
A Transformer model is built on layers of key components, mainly self-attention and feed-forward neural networks, and it uses positional encoding to keep track of the order of tokens.
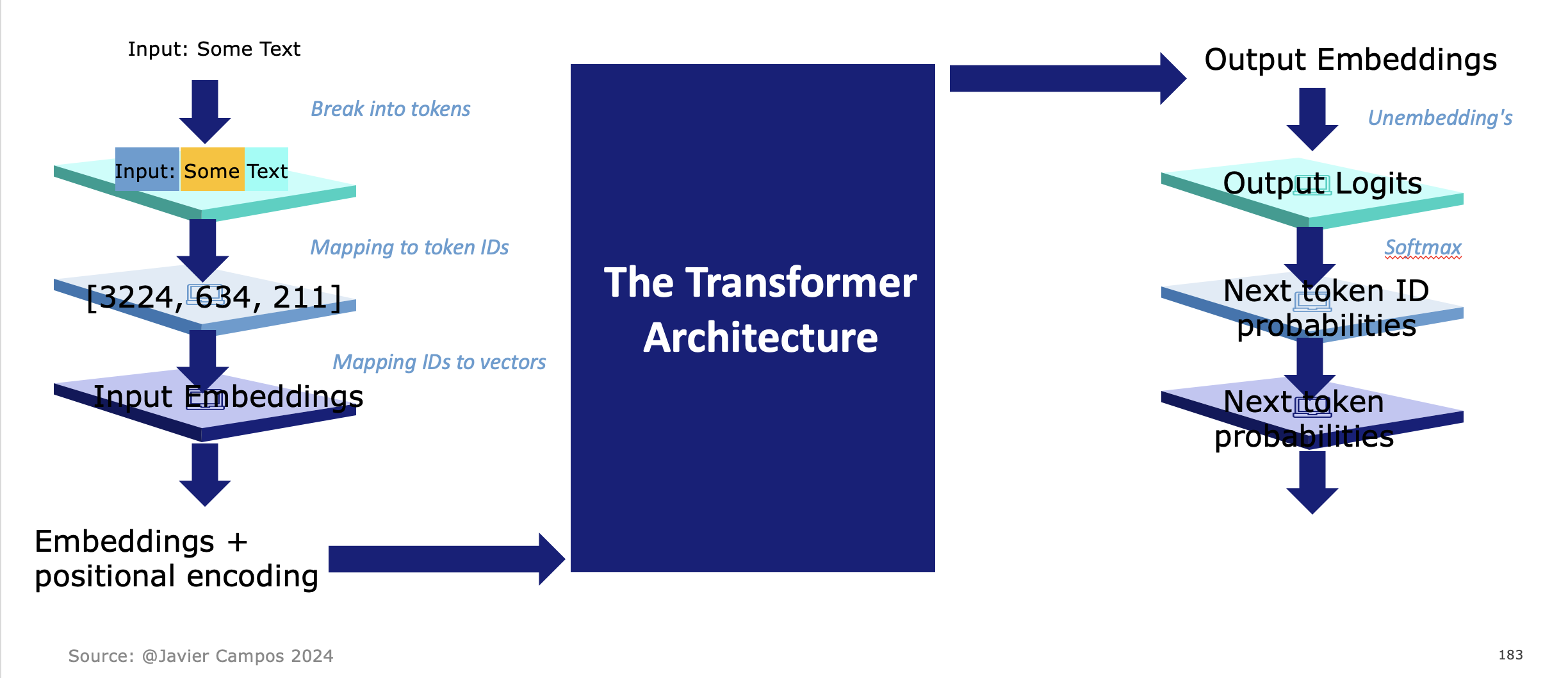
1. Input Embeddings & Positional Encoding
Before feeding text into the model, each word or token is transformed into a vector representation called an embedding. Since Transformers don’t inherently know the order of tokens, a positional encoding is added to these embeddings to capture the sequence’s structure. This encoding allows the model to distinguish between the first and last word in a sentence, for example.
2. Self-Attention Mechanism
Self-attention is the core of the Transformer architecture. It allows each token to weigh the importance of every other token in the input sequence when making predictions or generating responses. In essence, it lets the model “attend” to all words at once, no matter their position, making it capable of understanding long-term dependencies far better than previous models.
-
How does self-attention work? The model creates three representations for each token: Query, Key, and Value vectors. These vectors are compared to each other to compute attention scores. Higher scores indicate stronger relationships between tokens. This process enables the model to decide which words or parts of the input sequence to focus on when generating output.
-
Multi-Head Attention: The attention mechanism is applied multiple times in parallel through multiple “heads” that focus on different parts of the input. This allows the model to capture various relationships and meanings in different contexts, making the Transformer more versatile and powerful.
3. Feed-Forward Networks
After self-attention, the processed data goes through fully connected feed-forward layers that further transform the token representations. These layers add complexity and depth to the model, enabling it to capture more abstract features in the data.
4. Stacking Layers
A Transformer is built by stacking multiple layers of self-attention and feed-forward networks. Each layer refines the model’s understanding of the data, and the output from the final layer is what the model uses to predict the next word in a sequence or answer a question.
Self-Attention: The Key to Understanding Context
Self-attention is what enables the model to weigh the significance of different tokens in relation to each other. Traditional models like RNNs struggled with long sentences because they processed input one word at a time, making it difficult to retain the context from earlier parts of the sequence. Transformers, by contrast, evaluate all tokens simultaneously, allowing them to better understand the entire sentence and the relationships within it.
For example, in the sentence “The cat sat on the mat,” the model can use self-attention to weigh the word “cat” more heavily when predicting the next token after “sat,” because the two are closely related. This simultaneous processing makes Transformers incredibly efficient at capturing complex dependencies within the text.
Scaling: Why More Parameters Matter
One of the most significant reasons for the success of Transformers is their ability to scale. Unlike earlier models, the performance of Transformers improves dramatically as they are trained with more parameters—the numerical values that a model adjusts during training to learn from data.
In simple terms, parameters are like “neurons” in a neural network. The more parameters, the more knowledge the model can store and the more nuanced its understanding of language becomes. Models like GPT-3 have billions of parameters (175 billion, to be exact), allowing them to generate highly coherent text, understand complex queries, and perform a wide range of language-related tasks with remarkable accuracy.
-
Why is scaling effective? As you increase the number of parameters, the model’s capacity to store and manipulate information grows, allowing it to learn more complex relationships between words and ideas. This is especially true in LLMs, where the combination of large datasets and many parameters gives rise to emergent behaviors—capabilities that weren’t explicitly programmed but arise naturally from the training process.
-
Trade-offs of scaling: However, increasing the number of parameters also comes with challenges. Larger models require vast amounts of computing power and energy to train, making them more resource-intensive. Additionally, the more complex a model becomes, the harder it is to interpret its decisions and behaviors, leading to concerns about explainability and control.
Why Transformers Outperform Traditional Models
Transformers outperform older architectures like RNNs and LSTMs in several key areas:
-
Parallel Processing: The self-attention mechanism allows Transformers to process entire sequences at once, making them much faster than sequential models.
-
Long-Range Dependencies: Transformers can easily capture long-term dependencies between tokens, making them particularly good at understanding the context in long documents or conversations.
-
Scalability: Their ability to scale with additional parameters and data has made Transformers the dominant architecture in NLP today, with models like GPT-4 and BERT pushing the boundaries of what’s possible.
Looking Ahead: From Architecture to Application
In the next post, we’ll dive deeper into how unsupervised learning trains these models and leads to surprising emergent behaviors. But for now, it’s essential to appreciate that Transformers form the foundation of modern AI, allowing us to build more sophisticated systems and unlock new capabilities in natural language understanding and generation.
Stay tuned for more insights as we continue this journey through the LLM landscape!
🚀 Next in the Series: “Unsupervised Learning and Emergent Behaviors in LLMs”